

This project adresses the improvement of performance in supervised learning algorithms through feature selection. This process involves identifying relevant data subsets that optimize the accuracy of trained algorithms, focusing on eliminating unnecessary or redundant predictor variables. Current data sets are highly multidimensional, generating noise and increasing computational costs, making feature selection essential for the efficiency and effectiveness of machine learning.
The central problem of the research is handling highly multidimensional data sets in supervised learning algorithms. These sets contain numerous predictor variables that can cause noise and significantly increase computational costs, negatively affecting algorithm performance. Therefore, an effective methodology is required to identify and select the most relevant features and discard the unnecessary ones.
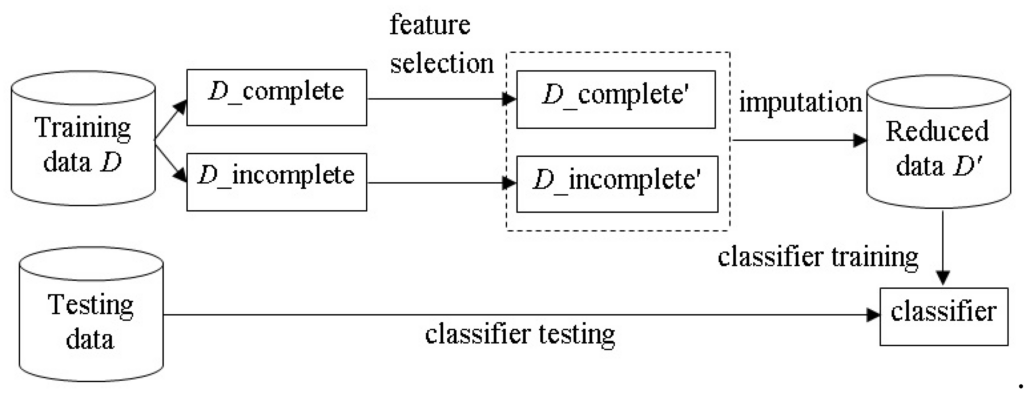
The proposed solution focuses on implementing wrapper methods, specifically Sequential Feature Algorithms (SFA), like the Sequential Forward Selection (SFS) and Sequential Floating Forward Selection (SFFS) methods. These methods aim to optimize subsets of predictor variables, thereby improving the performance of decision trees in supervised learning. Robust evaluation is carried out through cross-validation, averaging results from multiple experiments to ensure reliability. SFS and SFFS differ in their strategy: while SFS sequentially selects the best variables, SFFS enhances the subset by adding and removing variables to optimize performance.
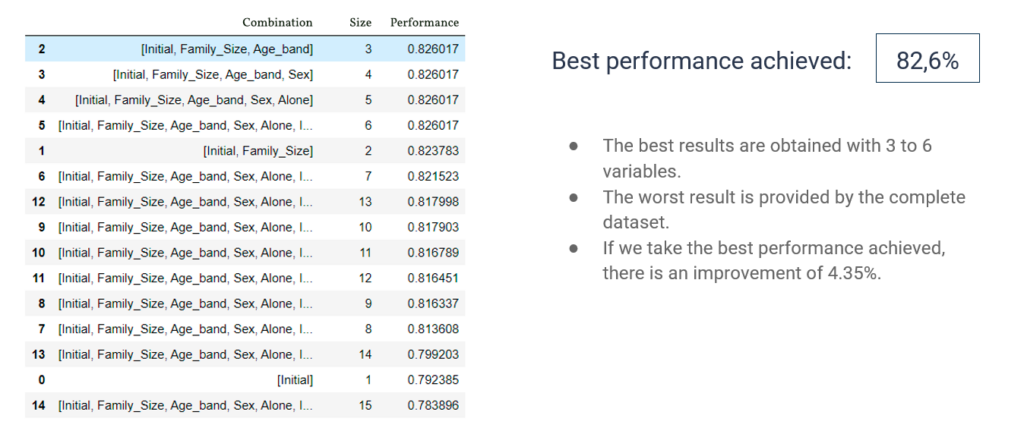
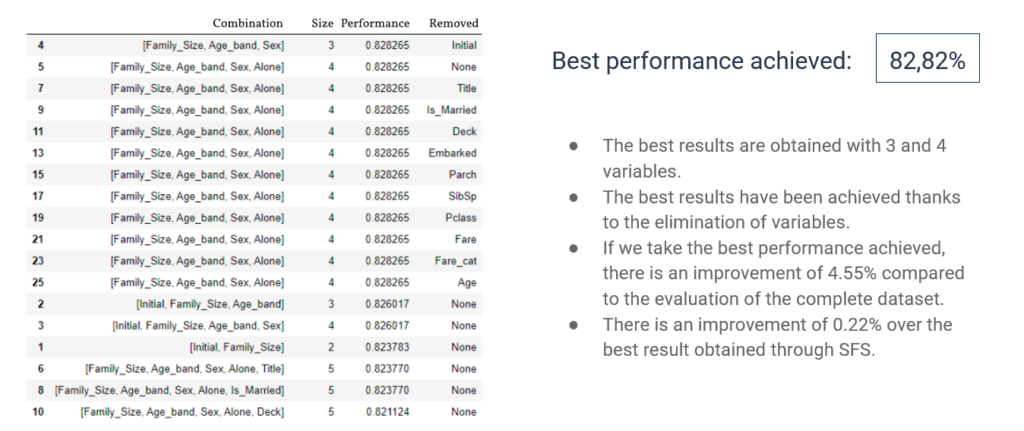
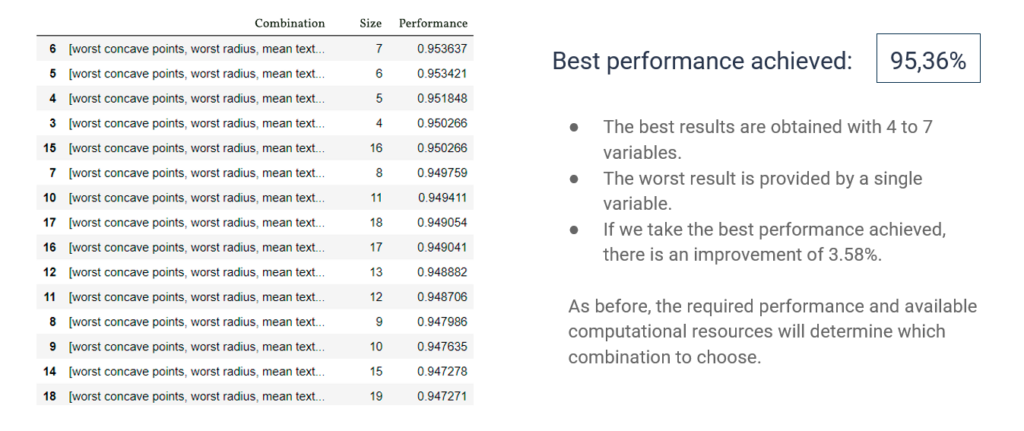
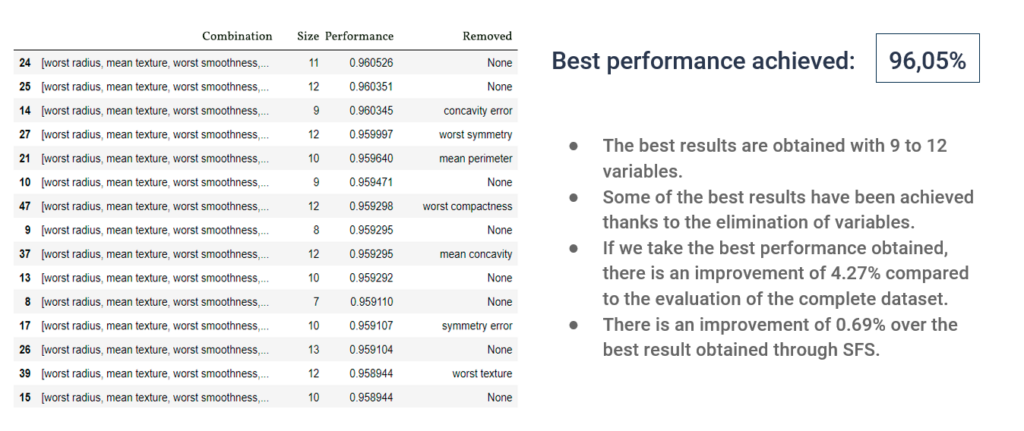
Applied to data sets of the Titanic and breast cancer, both methods demonstrated significant improvements in decision tree performance, with smaller and more efficient subsets compared to using complete data sets. These results underline the importance of effective feature selection in reducing computational costs and improving accuracy in supervised learning.
For the two datasets we have used, applying the feature selection algorithms has improved performance. Furthermore, the number of variables needed to achieve the best performances is significantly lower than that of the initial set, and therefore the computational cost will also be lower.
In the first dataset, we have information about Titanic passengers, and the target variable is whether they survive. In the second dataset, we have information about specific characteristics of breast cancers, and the target variable is whether the tumor is malignant.